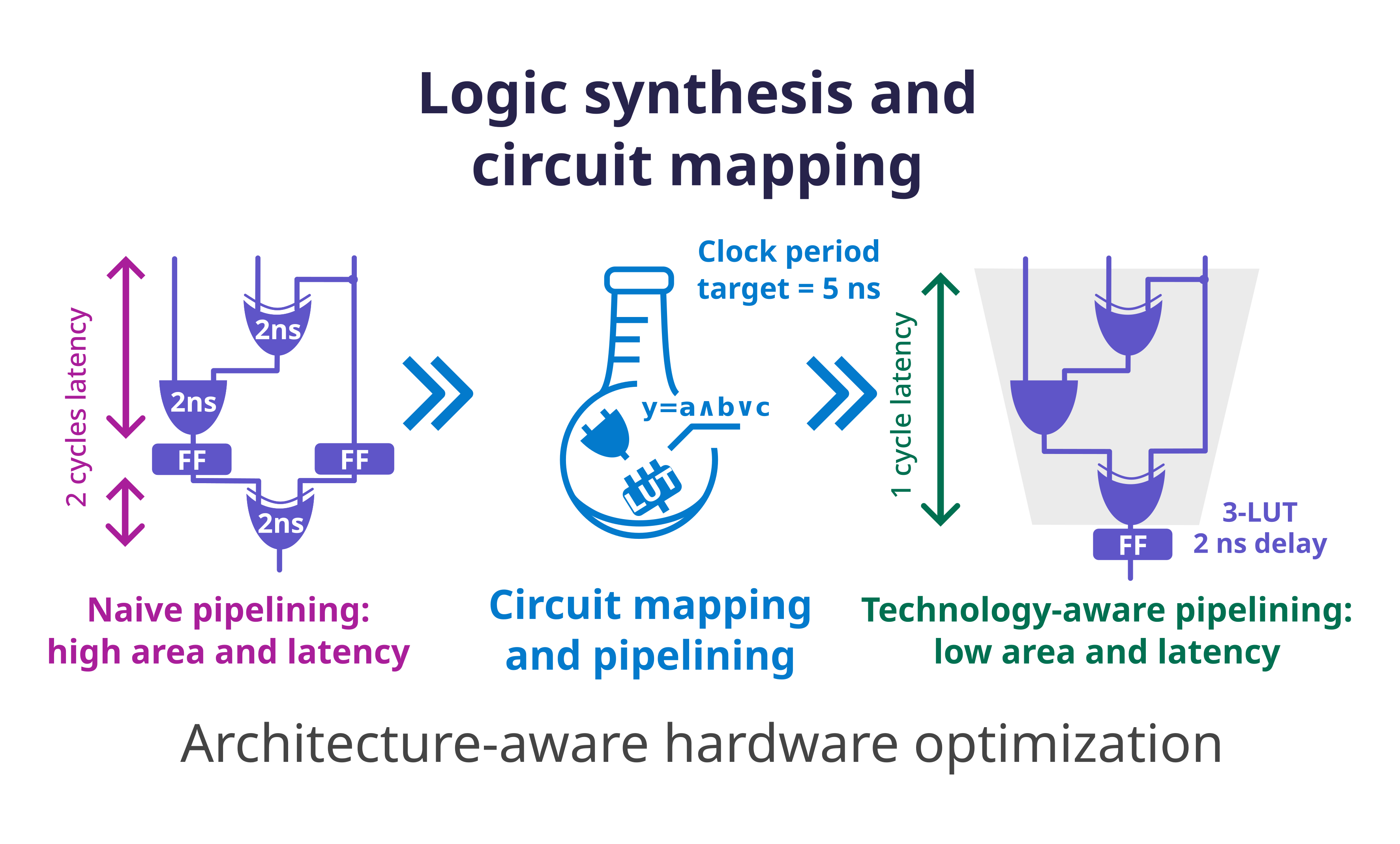
Specialized hardware accelerators (e.g., ASICs, FPGAs) are a promising solution for dealing with our increasing computational demands, as they offer high parallelism and energy efficiency. However, a major barrier to their global success is the difficulty of hardware design. The research of DYNAMO focuses on methods to make the design of high-quality hardware accelerators broadly accessible, fast, and reliable. Our research spans several areas of computer science and electrical engineering, including compilers, formal methods, electronic design automation, digital hardware design, and computer architecture.
Our research outputs are publicly available on our GitHub page or on the pages of our collaborators (e.g., Dynamatic), and our papers are usually accompanied by reproducible artifacts on Zenodo. Please check our publications page for links associated with each paper. Our research is generously supported by the Swiss National Science Foundation, Horizon Europe, Innosuisse, ETH Future Computing Laboratory, Cadence Design Systems, Google, AMD, and imec.
Research Areas



Research Topics